• Astra DB Client
1. Overview¶
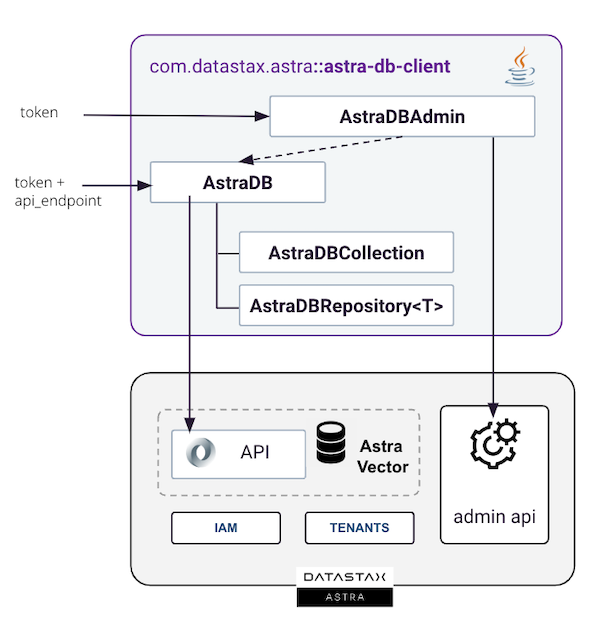
The Astra DB Client, as the name suggests, is a client library that interacts with the various APIs of the Astra DataStax Platform. It enables users to connect to, utilize, and administer the Astra Vector product. The library encompasses two distinct clients working in tandem:
-
AstraDBAmin: This class is initialized exclusively using an organization administrator token and enables the creation and deletion of databases via the DevOps API. It facilitates automation and administration within your organization's tenant.
-
AstraDB: This is the primary endpoint, connecting exclusively to a single database to perform all operations for your applications. It requires initialization with a database administrator token and also necessitates the API endpoint of your database.
-
AstraDBCollection: This client class facilitates all operations at the collection level, including find(), insert(), and delete(). It is instantiated through the AstraDB class and accommodates operations on both vector and non-vector collections.
-
AstraDBRepository
: This class represents a specialized form of AstraDBCollection designed for use with Java beans (T). It embodies the repository pattern, streamlining the management and access of domain entities.
Reference Architecture
2. Prerequisites¶
Java and Apache Maven/Gradle Setup
- Install Java Development Kit (JDK) 11++
Use the java reference documentation to install a Java Development Kit (JDK) tailored for your operating system. After installation, you can validate your setup with the following command:
- Install Apache Maven (3.9+) or Gradle
Samples and tutorials are designed to be used with Apache Maven. Follow the instructions in the reference documentation to install Maven. To validate your installation, use the following command:
Astra Environment Setup
- Create your DataStax Astra account:
- Create an organization level Astra Token
Once logged into the user interface, select settings from the left menu and then click on the tokens tab to create a new token.
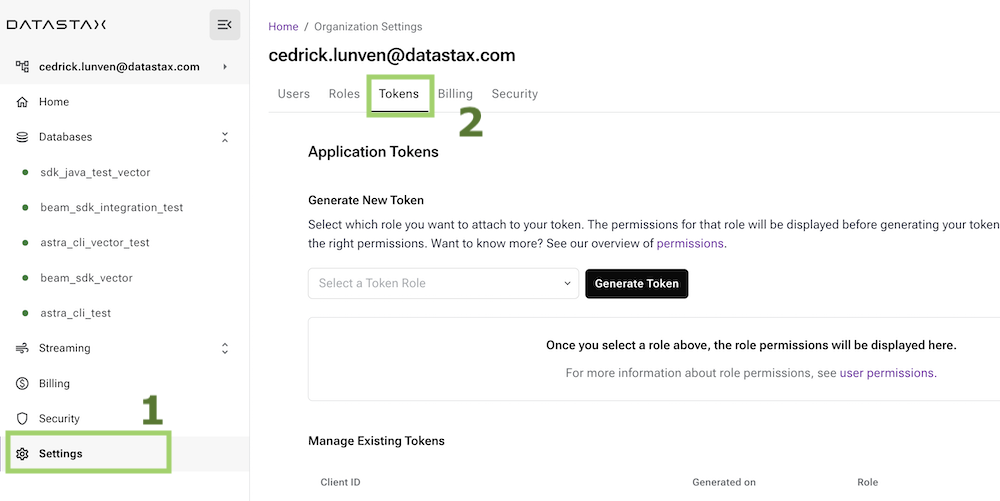
You want to pick the following role:
| Properties | Values |
|---|---|
| Token Role | Organization Administrator |
The Token contains properties Client ID, Client Secret and the token. You will only need the third (starting with AstraCS:)
{
"ClientId": "ROkiiDZdvPOvHRSgoZtyAapp",
"ClientSecret": "fakedfaked",
"Token":"AstraCS:fake" <========== use this field
}
To operate with AstraDBAdmin, this specific organization-level token is required. For tasks involving AstraDB at the database level, a database-level token suffices. The procedure for creating such a token is detailed in subsequent sections.
3. Getting Started¶
Project Setup¶
Project Setup
- If you are using
MavenUpdate yourpom.xmlfile with the latest version of the Vector SDK
<dependency>
<groupId>com.datastax.astra</groupId>
<artifactId>astra-db-client</artifactId>
<version>${latest}</version>
</dependency>
- If you are using gradle change the
build.dgradlewith
Quickstart¶
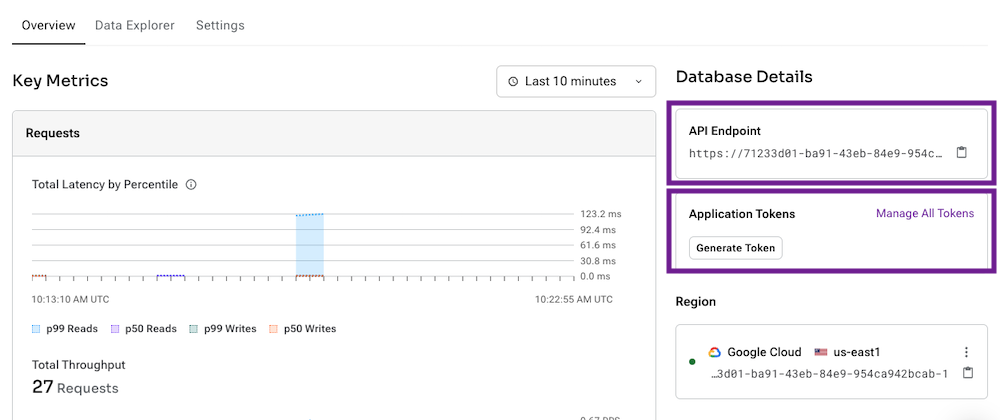
Getting your token and Api Endpoint
AstraDB class is the entry point of the SDK. It enables interactions with one particular database within your Astra environment. The initialization can be achieved in multiple ways:
- Using a
tokenalong with theapi_endpoint. Both are retrieved from the Astra user interface. - Using a
tokenwith the database identifier and eventually the region.
To establish this connection, you can generate a token via the user interface. This token will be assigned the Database Administrator permission level, which grants sufficient privileges for interacting with a specific database.
The api_endpoint is obtained from the user interface. It adheres to the following pattern: https://{database-identifier}-{database-region}.apps.astra.datastax.com.
4. Reference Guide¶
Connection¶
Connect to AstraDB Vector by instantiating AstraDB class.
General Information
- Connection is stateless and thread safe, we initialize an HTTP client.
- At initialization a check is performed to ensure enpoint and token are valid.
- If not provided default keyspace is
default_keyspace. - Database UUID and region are part of the endpoint URL.
- Signatures and JavaDoc
AstraDB(String token, String apiEndpoint);
AstraDB(String token, String apiEndpoint, String keyspace);
AstraDB(String token, UUID databaseId);
AstraDB(String token, UUID databaseId, String keyspace);
AstraDB(String token, UUID databaseId, String region, String keyspace);
AstraDB(String token, UUID databaseId, String region, AstraEnvironment env, String keyspace);
- Sample Code
Working with Collections¶
Overview¶
Overview
AstraDB is a vector database that manages multiple collections. Each collection (AstraDBCollection) is identified by a name and stores schema-less documents. It is capable of holding any JSON document, each uniquely identified by an _id. Additionally, a JSON document within AstraDB can contain a vector. It is important to note that all documents within the same collection should utilize vectors of the same type, characterized by consistent dimensions and metrics.

Create Collection¶
Create a collection in the current database.
General Information
- A collection name is unique for a database
- A collection name should match
[A-Za-z_] - Method
createCollection()method returns an instance ofAstraDBCollection - Collection is created only if it does not exist
- If collection exists, a check is performed for vector dimension and metric
- There are a maximum of 5 collections per database
- If not provided, default metric is
cosine - Vector
dimensionand ametricare set at creation and cannot be changed later - The
dimensionis the size of the vector - The
metricis the way the vector will be compared. It can becosine,euclideanordot_product
- Signature and Javadoc 🔗
AstraDBCollection createCollection(String name);
AstraDBCollection createCollection(String name, int vectorDimension);
AstraDBCollection createCollection(String name, int vectorDimension, SimilarityMetric metric);
AstraDBCollection createCollection(CollectionDefinition def);
- Sample Code
- Data API
Below is the associated REST API payload
Create a collection with no vector
Create a collection with a vector
{
"createCollection": {
"name": "collection_vector",
"options": {
"vector": {
"dimension": 14,
"metric": "cosine"
}
}
}
}
Create a collection with a vector and indexing options
{
"createCollection": {
"name": "collection_deny",
"options": {
"vector": {
"dimension": 14,
"metric": "cosine"
},
"indexing": {
"deny": [
"blob_body"
]
}
}
}
}
List Collections¶
List collections in the current database with their attributes. (similarity, dimension, indexing...)
General Information
- A database can have up to 5 collections.
- A collection with a vector has a set of options like dimension, similarity and indexing.
- Signature and Javadoc 🔗
- Sample Code
- Data API
Below is the associated REST API payload
Find Collection¶
Retrieve collection definition from its name.
General Information
- name is the identifier of the collection.
- Signature and Javadoc 🔗
Optional<CollectionDefinition> findCollectionByName(String name);
boolean isCollectionExists(String name);
- Sample Code
- Data API
list collections
Delete Collection¶
Delete a collection from its name
General Information
- If the collection does not exist, the method will not return any error.
- Signature and Javadoc 🔗
- Sample Code
- Data API
delete a collection from its name
Working with Documents¶
Insert One¶
You can insert unitary record with the function insertOne(). Multiple signatures are available to insert a document.
General Informations
- If not provided, the identifier is generated as a java UUID
- The method always return the document identifier.
- All attributes are optional (schemaless)
- You attribute names should match
[A-Za-z_] - All Java simple standard types are supported
- Nested object are supported
- A field value should not exceed 5Kb
- Each attribute is indexed and searchable
- A vector cannot be filled only with 0s, it would lead to division by 0
- Signature
JsonDocumentMutationResult
insertOne(JsonDocument doc);
CompletableFuture<JsonDocumentMutationResult>
insertOneASync(JsonDocument doc);
DocumentMutationResult<DOC>
insertOne(Document<DOC> document);
CompletableFuture<DocumentMutationResult<DOC>>
insertOneASync(Document<DOC> document);
- Sample Code
- Data API Payload
{
"insertOne": {
"document": {
"product_name": "HealthyFresh - Chicken raw dog food",
"product_price": 9.99,
"_id": "f2472946-cc9f-4ad1-801d-f1cf21d8cb38",
"$vector": [
0.3, 0.3, 0.3, 0.3, 0.3,
0.3, 0.3, 0.3, 0.3, 0.3,
0.3, 0.3, 0.3, 0.3
]
}
}
}
Upsert One¶
General Informations
insert*will give you an error when id that already exist in the collection is provided.upsert*will update the document if it exists or insert it if it does not.
- Signatures
JsonDocumentMutationResult
upsertOne(JsonDocument doc);
CompletableFuture<JsonDocumentMutationResult>
upsertOneASync(JsonDocument doc);
DocumentMutationResult<DOC>
upsertOne(Document<DOC> document);
CompletableFuture<DocumentMutationResult<DOC>>
upsertOneASync(Document<DOC> document);
- Sample Code
- Data API Payload
{
"findOneAndReplace": {
"filter": {
"_id": "1"
},
"options": {
"upsert": true
},
"replacement": {
"a": "a",
"b": "updated",
"_id": "1"
}
}
}
Insert Many¶
General Informations
- The underlying REST API is paged. The maximum page size is 20.
- To perform bulk loading, distribution of the workload is recommended
insertMany**Chunked**are a helper to distribute the workload- If more than 20 documents are provided chunking is applied under the hood
- Signatures
// Use a json String
List<JsonDocumentMutationResult>
insertMany(String json);
CompletableFuture<List<JsonDocumentMutationResult>>
insertManyASync(String json);
// Use an Array of JsonDocuments
List<JsonDocumentMutationResult>
insertMany(JsonDocument... documents);
CompletableFuture<List<JsonDocumentMutationResult>>
insertManyASync(JsonDocument... documents);
// Use a list of JsonDocument
List<JsonDocumentMutationResult>
insertManyJsonDocuments(List<JsonDocument> documents);
CompletableFuture<List<JsonDocumentMutationResult>>
insertManyJsonDocumentsASync(List<JsonDocument> documents);
// Use an Array of Document<T>
List<DocumentMutationResult<DOC>>
insertMany(Document<DOC>... documents);
CompletableFuture<List<DocumentMutationResult<DOC>>>
insertManyASync(Document<DOC>... documents);
// Use a list of Document<T>
List<DocumentMutationResult<DOC>>
insertMany(List<Document<DOC>> documents);
CompletableFuture<List<DocumentMutationResult<DOC>>>
insertManyASync(List<Document<DOC>> documents);
- Sample Code
- Data API
Insert Many with ordered true
{
"insertMany": {
"options": {
"ordered": false
},
"documents": [
{
"product_name": "test1",
"product_price": 12.99,
"_id": "doc1"
},
{
"product_name": "test2",
"product_price": 2.99,
"_id": "doc2"
}
]
}
}
Insert Many with ordered false
{
"insertMany": {
"options": {
"ordered": true
},
"documents": [
{
"firstName": "Lucas",
"lastName": "Hernandez",
"_id": "1"
},
{
"firstName": "Antoine",
"lastName": "Griezmann",
"_id": "2"
},
{
"firstName": "N'Golo",
"lastName": "Kanté",
"_id": "3"
},
{
"firstName": "Paul",
"lastName": "Pogba",
"_id": "4"
},
{
"firstName": "Raphaël",
"lastName": "Varane",
"_id": "5"
},
{
"firstName": "Hugo",
"lastName": "Lloris",
"_id": "6"
},
{
"firstName": "Olivier",
"lastName": "Giroud",
"_id": "7"
},
{
"firstName": "Benjamin",
"lastName": "Pavard",
"_id": "8"
},
{
"firstName": "Kylian",
"lastName": "Mbappé",
"_id": "9"
}
]
}
}
Insert Many Chunked¶
- Signatures
// Insert a list of json documents
List<JsonDocumentMutationResult>
insertManyChunkedJsonDocuments(List<JsonDocument> documents, int chunkSize, int concurrency);
CompletableFuture<List<JsonDocumentMutationResult>>
insertManyChunkedJsonDocumentsAsync(List<JsonDocument> documents, int chunkSize, int concurrency);
// Insert a list of documents
List<DocumentMutationResult<DOC>>
insertManyChunked(List<Document<DOC>> documents, int chunkSize, int concurrency);
CompletableFuture<List<DocumentMutationResult<DOC>>>
insertManyChunkedASync(List<Document<DOC>> documents, int chunkSize, int concurrency);
Upsert Many¶
- Signatures
// Use a json String
List<JsonDocumentMutationResult>
upsertMany(String json);
CompletableFuture<List<JsonDocumentMutationResult>>
upsertManyASync(String json);
// Use a list of JsonDocument
List<JsonDocumentMutationResult>
upsertManyJsonDocuments(List<JsonDocument> documents);
CompletableFuture<List<JsonDocumentMutationResult>>
upsertManyJsonDocumentsASync(List<JsonDocument> documents);
// Use a list of Document<T>
List<DocumentMutationResult<DOC>>
upsertMany(List<Document<DOC>> documents);
CompletableFuture<List<DocumentMutationResult<DOC>>>
upsertManyASync(List<Document<DOC>> documents);
Find By Id¶
- Signatures
Optional<JsonDocumentResult> findById(String id);
Optional<DocumentResult<T>> findById(String id, Class<T> bean);
Optional<DocumentResult<T>> findById(String id, DocumentResultMapper<T> mapper);
boolean isDocumentExists(String id);
- Sample Code
- Data API
Find By Vector¶
- Signatures
Optional<JsonDocumentResult> findOneByVector(float[] vector);
Optional<DocumentResult<T>> findOneByVector(float[] vector, Class<T> bean);
Optional<DocumentResult<T>> findOneByVector(float[] vector, DocumentResultMapper<T> mapper);
- Sample Code
Find One¶
Introducing SelectQuery
Under the hood every search against the REST Api is done by providing 4 parameters:
$filter: which are your criteria (where clause)$projection: which list the fields you want to retrieve (select)$sort: which order the results in memory (order by) or the vector search (order by ANN)$options: that will contains all information like paging, limit, etc.
The SelectQuery class is a builder that will help you to build the query. It is a fluent API that will help you to build the query.
As for findById and findByVector there are 3 methods available to retrieve a document. If the SelectQuery has multiple
matches objects only the first will be returned. In doubt use find() or even better findPage() not to exhaust all the
collection.
Optional<JsonDocumentResult> findOne(SelectQuery query);
Optional<DocumentResult<DOC>> findOne(SelectQuery query, Class<T> clazz);
Optional<DocumentResult<DOC>> findOne(SelectQuery query, ResultMapper<T> mapper);
Here is a sample class detailing the usage of the findOne method.
- Data API
Find with a Greater Than or Equals
Find with a Less Than
Find with a Less Than or Equals
Find with a Equals
Find with a Not Equals
Find with a Exists
Find with a And
{
"find": {
"filter": {
"$and": [
{
"product_price": {
"$exists": true
}
},
{
"product_price": {
"$ne": 9.99
}
}
]
}
}
}
Find with a In
Find with a Not In
Find with a Size
Find with a Less Than Instant
Find¶
Reminders on SelectQuery
Under the hood every search against the REST Api is done by providing 4 parameters:
$filter: which are your criteria (where clause)$projection: which list the fields you want to retrieve (select)$sort: which order the results in memory (order by) or the vector search (order by ANN)$options: that will contains all information like paging, limit, etc.
The SelectQuery class is a builder that will help you to build the query. It is a fluent API that will help you to build the query.
Important
With the Json API all queries are paged. The maximum page size is 20. The method findAll() and find() will fetch the
pages one after the other until pagingState is null. Use those functions with caution.
- To retrieve every document of a collection use
findAll()
- Find with a
Query
- To perform semantic search use
findVector()
Paging¶
Every request is paged with the Json API and the maximum page size is 20. The methods return Page
- Find Page
The signature are close to the find(). Reason is that find() is using findPage under the hood. The difference is that it will exhaust all the pages
and return a Stream<JsonResult>.
Page<JsonResult> jsonResult = findPage(SelectQuery query);
Page<Result<T>> jsonResult2 = findPage(SelectQuery query, Class<T> clazz);
Page<Result<T>> jsonResult3 = findPage(SelectQuery query, ResultMapper<T> clazz);
Update One¶
Allow to update an existing document:
Update Many¶
Allow to update a set of document matching a request.
Delete One¶
Use to delete an existing document.
Delete Many¶
Used to delete a set of document matching a request.
Clear¶
Used to empty a collection
Object Mapping¶
Overview
Instead of interacting with the database with key/values you may want to
associate an object to each record in the collection for this you can use CollectionRepository. If we reproduce the sample before

Repository Pattern¶
Instead of working with raw JsonDocument you can work with your own object. The object will be serialized to JSON and stored in the database. You do not want to provide a ResultMapper each time but rather use the repository pattern.
We will follow the signature of the CrudRepository from Spring Data.
long count();
void delete(T entity);
void deleteAll();
void deleteAll(Iterable<? extends T> entities);
void deleteAllById(Iterable<? extends ID> ids);
void deleteById(ID id);
boolean existsById(ID id);
Iterable<T> findAll();
Iterable<T> findAllById(Iterable<ID> ids);
Optional<T> findById(ID id);
<S extends T> S save(S entity);
Iterable<S> saveAll(Iterable<S> entities);
Create collection¶
Insert One¶
Insert Many¶
Find One¶
- To get a single document use
findById()orfindByVector()
Find¶
- To perform search use
find()
- To perform semantic search use
findVector()
Update One¶
Update Many¶
Delete One¶
Delete Many¶
Clear¶
Working with databases¶
Connection¶
About token permissions
To work with Databases you need to use a token with organization level permissions. You will work with the class AstraDBClient
To establish a connection with AstraDB using the client SDK, you are required to supply a token. This token enables two primary connection modes:
-
Direct database-level connection, facilitating access to a specific database. It is the one decribe above and primay way of working with the SDK.
-
Organization-level connection, which allows interaction with multiple databases under your organization. This is what we will detailed now
AstraDBClient class is used to facilitate interactions with all components within your Astra organization, rather than limiting operations to a single database.
This approach enables a broader scope of management and control across the organization's databases. The token used for this connection must be scoped to the organization with
| Properties | Values |
|---|---|
| Token Role | Organization Administrator |
List databases¶
Create database¶
To create a database you need to use a token with organization level permissions. You will work with the class AstraDBClient
Find database¶
- Accessing object
AstraDB
Delete database¶
- Delete Databases with
deleteDatabase
The function can take a database identifier (uuid) or the database name.
Working with Keyspaces¶
Create Keyspace¶
Create a keyspace in the current database with the given name.
General Information
- Default keyspace is
default_keyspace - If the keyspace already exist, the method will return 'KeyspaceAlreadyExistException'
- Signature and Javadoc 🔗
void createKeyspace(String databaseName, String keyspaceName);
void createKeyspace(UUID databaseId, String keyspaceName);
- Sample Code
Delete Keyspace¶
Delete a keyspace in the current database from its name.
General Information
- Default keyspace is
default_keyspace - If the keyspace does not exist, the method will return 'KeyspaceNotFoundException'
- Signature and Javadoc 🔗
void deleteKeyspace(String databaseName, String keyspaceName);
void deleteKeyspace(UUID databaseId, String keyspaceName);
- Sample Code
Find Keyspace¶
General Information
- A database is not limited in number of keyspaces.
- A keyspace is a logical grouping of collections.
- Default keyspace name is
default_keyspace
- Signature and Javadoc 🔗
boolean isKeyspaceExists(String keyspaceName);
Stream<String> findAllKeyspaceNames();
String getCurrentKeyspace(String keyspaceName);
void changeKeyspace(String keyspaceName);
- Sample Code
6. Class Diagram¶
7. Working with CassIO¶
Cassio is framework originally implement in Python to use Open Source Cassandra as a Vector Store. It has been partially ported in Java. Idea is java to use the same table created by CassIO.
Connection¶
General Information
- CassIO is a framework to use Open Source Cassandra as a Vector Store.
- Java portage is only 2 tables
metadata_vectorandclustered_metadata_vector - The tables are created with a specific schema to store vectors and metadata
- The indices are created to perform efficient search on the vector
- Signature and Javadoc 🔗
- Sample Code
MetadataVectorTable¶
General Information
- Creating a Cassandra table with the following schema and associated indices
- Sample Code
ClusteredMetadataVectorTable¶
General Information
- Creating a Cassandra table
- Sample Code